
저번 글에서는 결측치의 유형 (MCAR, MAR, MNAR)에 대해 작성하였는데, 이번 글에서는 결측치를 처리하는 방법, 즉 결측치 대치(Imputation)에 대해 알아보고자 합니다. 결측치 유형에 대해 궁금하시다면, 이 링크를 참고해주시면 됩니다. 물론 결측치가 많지 않을 경우에는 추가적인 전처리를 진행하지 않고 그대로 활용하거나 아예 제거하는 방법도 있지만, 대부분의 경우에는 결측치를 다른 값으로 대치하여 분석에 활용하게 됩니다.
1. Simple Imputation (단순 대치법)

Simple Imputation (단순 대치법)은 해당 열의 결측치들을 특정 하나의 값으로 대치하는 방법을 의미합니다. 결측치를 제외한 값들의 1) 평균(mean), 2) 중앙값(median), 3) 최빈값(mode) 등을 계산하고, 해당 값으로 결측치를 대치하는 방법입니다. 쉽고 빠르다는 장점을 가지고 있지만, 다른 열과의 관계를 고려할 수 없으며, 평균과 중앙값은 숫자형 데이터에만 활용할 수 있는 등 여러 단점들도 존재합니다.
2. k-NN Imputation

k-NN (k-Nearest Neighbors) Imputation은 우리가 흔히 알고있는 k-NN 알고리즘 기반의 방법으로, 단점이 많은 단순대치법의 대안으로 활용되었습니다. 위의 그림과 같은 feature space에서 k 개의 인접한 점들의 값을 바탕으로 결측치를 대치하게 됩니다. 인접한 점들은 결측치가 존재하는 점의 feature들과 유사한 특징을 가진다고 가정하기 때문에, 인접하는 점들의 값을 활용합니다. 단순대치법보다는 정확한 경우가 많지만, 데이터 크기가 방대해질수록 계산량도 매우 커지며, 이상치에 민감하다는 단점이 있습니다.
3. Multiple Imputation (다중 대치법)
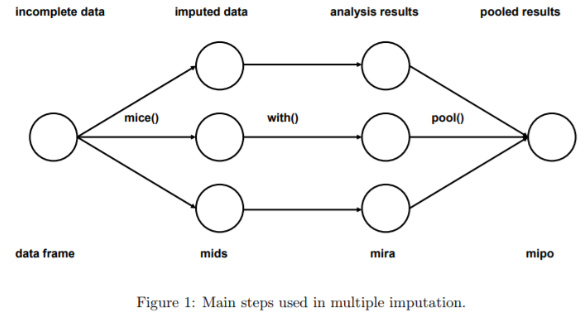
Multiple Imputation (다중 대치법)은 모든 결측치를 대치한 데이터셋을 여러 개 만든 이후, 각 데이터셋에 대해 표준적인 통계방법을 적용하고 통합하여 최종적인 결측치를 대치하는 방법입니다. 대부분의 다중 대치법은 앞서 설명한 결측치의 유형 중 MAR을 전제로 합니다. 다른 열로 결측치가 존재하는 열을 설명할 수 있어야, 다른 열들을 바탕으로 결측치를 추정할 수 있기 때문입니다. 대표적인 방법으로는 MICE (Multiple Imputation by Chained Equations)가 있으며, 간단한 과정은 다음과 같습니다.
- 1) 다른 변수들을 활용하여 결측치를 추정한 데이터셋을 여러 개 생성
- 2) 각각의 데이터셋에 대해 with()를 통해 회귀분석과 같이 원하는 통계 모형을 순서대로 적용
- 3) pool()을 통해 각 분석 결과를 하나로 통합
MICE에 대한 자세한 설명은 "mice: Multivariate imputation by chained equations in R" 논문[1]에 나와있습니다.
4. ML/DL 활용
마지막으로 언급할 방법은 Machine Learning/Deep Learning을 활용하는 방법입니다. 결측치 대치에 ML/DL을 활용한다고 해서 복잡한 과정을 진행하는 것은 아니고, 결측치가 없는 데이터셋을 바탕으로 모델을 학습시키고 Test data를 예측하는 것처럼 결측치를 추정하게 됩니다.
<참고>
[1] Van Buuren, S., & Groothuis-Oudshoorn, K. (2011). mice: Multivariate imputation by chained equations in R. Journal of statistical software, 45, 1-67.
[2] https://dslyh01.tistory.com/14?category=1059170
[Data Analysis] 결측치(Missing Value) 관련 정리
이번 글에서는 데이터 분석 관련 프로젝트를 진행하다보면 거의 직면할 수 밖에 없는 결측치에 대해 다뤄볼 것입다. 결측치를 많이 포함하는 데이터로 머신러닝/딥러닝 모델을 학습시키게 되
dslyh01.tistory.com
6 Different Ways to Compensate for Missing Data (Data Imputation with examples)
Popular strategies to statistically impute missing values in a dataset.
towardsdatascience.com
[4] https://rstudio-pubs-static.s3.amazonaws.com/192402_012091b9adac42dbbd22c4d07cb00d36.html
R강의7. 누락된 자료의 처리
누락된 자료의 처리* 통계 처리에 있어 missing data를 어떻게 처리할까 하는 문제는 연구자에게 가장 골치 아픈 문제 중 하나이다. 대부분의 통계 방법은 입력된 자료가 완전하고 누락된 자료가 없
rstudio-pubs-static.s3.amazonaws.com
[5] https://eda-ai-lab.tistory.com/14
결측치 처리 (Missing Value)
NOTE: 대부분의 내용은 https://blog.naver.com/tjdudwo93/220976082118을 기반으로 Titanic 데이터에 실습을 적용하는 것으로 진행됩니다. 군밤고굼님의 설명에 따르면 결측치를 살펴보는 과정은 아래와 같
eda-ai-lab.tistory.com
'Data Analysis > Imputation' 카테고리의 다른 글
| [Imputation] 결측치(Missing Value) 관련 정리 (2) | 2022.10.21 |
|---|

댓글