Arık, S. O., & Pfister, T. (2021). Tabnet: Attentive interpretable tabular learning. In AAAI (Vol. 35, pp. 6679-6687).
1. Introduction
- DNN이 이미지, 텍스트, 음성 등에 대한 분석에서는 우수한 성능을 바탕으로 활발히 적용되고 있지만, 정형 데이터에서는 트리 기반의 앙상블 모델들이 우세
- 정형 데이터에서 트리 기반의 앙상블 모델이 우세한 이유는 두 가지로, 첫 번째는 트리 기반의 모델이 가지는 이점들, 두 번째는 이전에 제안된 DNN 구조가 정형 데이터에 적합하지 않다는 것. 트리 기반의 모델이 가지는 이점들은 다음과 같음
- 정형 데이터에서 흔한 초평면 경계를 가진 manifold를 결정하는데 효율적 (간단하게 말해 고차원의 정형 데이터를 저차원으로 줄일 때, 각 데이터들 간의 집합을 구분 짓는 경계를 결정하는데 효율적이라는 것을 의미)
- 높은 해석력을 가지며, 이는 현실 세계에서 중요한 요소
- 빠른 학습 속도
- 그럼에도 정형 데이터에 딥러닝을 적용하는 것은 다음과 같은 이유로 가치가 있음
- 대용량의 데이터셋은 성능 개선에 기여할 것
- 정형 데이터를 비롯해 이미지와 같은 다양한 유형의 데이터를 효율적으로 인코딩
- 트리 기반 모델들과 비교하여 feature engineering에 대한 필요성이 적음
- Streaming 데이터에 대한 학습에 이점
- End-to-end 모델은 domain adaptation (domain shift를 감소시키는 것), generative modelling, 비지도 학습 등과 같은 다양한 응용이 가능
- 본 연구에서 제안하는 TabNet은 다음과 같이 기여할 수 있음
- 전처리없이 원천 데이터를 입력값으로 사용하며, gradient descent 기반 최적화를 사용하여 end-to-end 학습이 가능
- 각 결정 단계에서 변수를 선택하기 위해 sequential attention을 사용하며, 이는 학습 및 해석 능력을 향상시키는데 기여. 이러한 변수 선택은 입력값마다 다르게 진행 (instance-wise).
- 분류 및 회귀 문제에 대한 다양한 데이터셋에서 기존 모델들보다 우수하며, local 해석(변수 중요도 시각화, 변수들이 어떻게 결합하는지)과 global 해석(모델에 대한 변수들의 기여도 정량화)이 가능
- 정형 데이터에 처음으로 마스킹된 변수를 예측하기 위해 self-supervised learning을 적용하여 향상된 성능을 보여줌
2. Related work
- Feature Selection
- Global methods: 전체적인 훈련 데이터를 기반으로 변수 중요도 도출 (ex. Forward selection, Lasso regularization)
- Instance-wise: 각 입력값마다 변수들을 다르게 선택하는 방식
- Soft feature selection with controllable sparsity in end-to-end learning: 단일 모델이 변수 선택과 결과 출력을 같이 진행하여 보다 우수한 성능 도출 (TabNet에서 활용할 방식)
- Tree-based Learning: 모형의 분산을 줄이기 위해 앙상블 모형이 개발되었으며, Random forests, XGBoost, LightGBM이 최근에 가장 활발히 적용
- Integration of DNNs into DTs: DNN과 DT를 결합하려는 기존 연구들은 중복으로 인한 비효율적 학습, 자동적인 변수 선택 기능 상실 등과 같은 한계가 존재. TabNet은 기존 연구들과 달리 sequential attention을 통해 controllable sparsity를 가진 soft feature selection 진행
- Self-supervised Learning: 데이터에 결측치들이 다수 존재할 경우, 다른 변수들을 활용하여 비지도 학습 기반으로 결측치를 추정하는 것을 통해 원천 데이터의 질을 높이고, 최종적으로 학습 모델의 성능을 높이는 방식
3. TabNet for Tabular Learning
- TabNet은 Mask block을 통해 변수 선택을 진행하며, 이러한 과정을 바탕으로 결정 경계를 형성하는 방법이 DT와 유사

- TabNet은 DT와 유사한 과정, 다음과 같은 이점들을 바탕으로 기존 DT 기반 방법론보다 우수한 성능을 보여줌
- 데이터로부터 학습된 sparse instance-wise feature selection 사용
- 각 단계가 선택된 변수들을 바탕으로 결정에 일부 기여하며, 연속된 다단계의 아키텍쳐로 구성
- 선택된 변수들의 비선형 과정을 통해 학습 능력 개선
- 더 높은 차원 및 단계를 통해 앙상블 과정 모방

- TabNet encoder 아키텍처는 기본적으로 1) Feature transformer, 2) Attentive transformer, 3) Feature Masking, 3단계가 반복해서 이루어짐
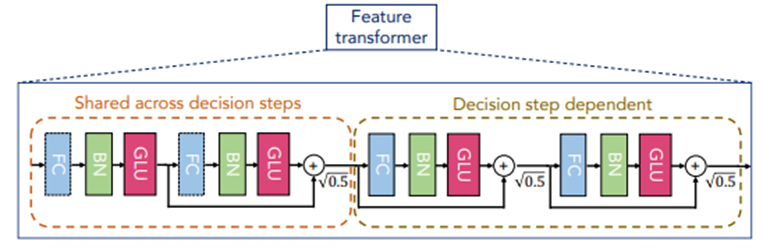
- Feature transformer: 첫 번째 단계에서는 Batch normalization (BN)을 거친 input 데이터가 입력되고, 이후 단계에서는 masking된 input 데이터가 입력. Feature transformer 블록 내에서는 FC(Fully-Connected)-BN-GLU(Gated Linear unit) 과정이 총 4번 반복되며, 앞의 두 과정은 모든 결정 단계에서 공유되고, 뒤의 두 과정은 해당 결정 단계에서만 활용
- Split: GLU의 결과물의 반은 attentive transformer의 input으로 활용되고, 나머지 반은 ReLU activation의 input으로 활용. (ReLU의 결과를 통해 feature importance 및 attributes를 도출)

- Attentive transformer: Prior Scale은 이전 결정 단계에서 각 변수들이 얼마나 활용되었는지 집계한 정보이며, Sparsemax는 Softmax보다 sparsity를 고려한 함수로, 0~1 사이의 값이 계산되지만 0이나 1에 가까운 극단적인 값들이 도출 (sparsemax를 활용하는 것을 통해 각 결정 단계마다 중요도가 떨어지는 변수에 learning capacity가 낭비되는 것을 방지). 이러한 두 과정을 거치며, 각 변수별로 중요도가 고려된 값들이 생성
- Feature Masking: Attentive transformer의 결과물과 변수들을 곱하는 것을 통해 sparse feature selection 과정이 진행. Masking의 결과물은 다시 feature transformer의 input으로 활용
- Interpretability: 변수 중요도의 해석은 Attentive transformer의 결과물을 바탕으로 진행되며, 0에 가까울수록 중요도가 낮고 값이 클수록 중요도가 높은 것을 의미

- Tabular self-supervised learning: 원천 데이터에 존재하는 결측치들을 다른 컬럼을 활용하여 추정하는 것을 통해, 원본 데이터의 질을 향상시켜 성능 개선
4. Experimetns

- Instance-wise feature selection: 우선 변수 선택과 관련된 검증 수행. 총 6개의 합성 데이터셋을 활용하여 진행되었으며, Syn1~3은 모든 instance에서 같은 중요 변수를 가졌고, Syn4~6은 instance별로 중요 변수가 다름. Syn1~3의 경우, TabNet은 global feature selection 방법들과 유사한 정확도를 보여줬으며, 이는 global feature selection도 잘 수행한다는 것을 의미. Syn4~6의 경우, instance-wise feature selection을 통해 불필요한 변수들을 제거하여 성능 향상


- Performance on real-world datasets: 다양한 데이터들을 기반으로 XGBoost, LightGBM, CatBoost 등의 방법론들과 비교분석을 수행하였으며, instance-wise feature selection 등의 이점을 통해 TabNet이 가장 우수한 성능을 보여줌

- Interpretability: 가장 왼쪽에 있는 그림은 집계한 결과이며, 밝게 나타나는 부분이 중요 변수를 의미. Syn4는 Syn2와 달리 instance별로 중요 변수가 달라지는 것을 확인할 수 있음

- Self-supervised learning: Self-supervised learning이 수행된 결과가 기존보다 향상된 성능을 보여주며, 특히 라벨링이 되지 않은 데이터가 많은 데이터셋에서 두드러짐. 모델 수렴도 기존보다 빠르게 이루어졌으며, 이는 연속적인 학습과 domain adaptation에 유용
5. Conclusions
- 각 결정 단계마다 유의미한 변수들을 선택하기 위해 Sequential attention mechanism 사용
- Instance-wise feature selection을 통해 모델의 성능을 향상시키고, 보다 해석력있는 시각화 결과를 도출
- 다양한 분야들의 정형 데이터를 바탕으로 TabNet이 기존 방법론들보다 우수하다는 것을 증명
- Self-supervised learning을 통해 빠른 수렴과 성능을 개선
추후 논문 리뷰 외에도 실제 데이터를 활용하여 실습을 진행할 계획입니다. 개인적으로 공부를 하며 작성한 리뷰이기에 잘못된 부분이 있을 수 있습니다. 잘못 이해한 부분이 있다면 언제든지 댓글로 알려주시길 바랍니다. 감사합니다:)
<참고>
[논문 리뷰 및 코드구현] TABNET
[Review] TABNET: Attentive Interpretable Tabular Learning (2019) 이번 포스팅은 Tabular(정형) 데이터에 적합한 딥러닝 모델이라 주장하는 TABNET 논문 리뷰를 해보겠습니다. 궁금한점이나 해석이 잘못된 부분..
wsshin.tistory.com
https://huidea.tistory.com/292
[Deep learning][논문리뷰] Tabnet : Attentive Interpretable Tabular Learning
* concept 입력된 table (tabular) 데이터에서 Feature를 masking하며 여러 step을 거쳐서 학습 —> 각 step별 feature들의 importance 파악 (설명력 확보) —> masking 으로 중요한 feature 들만 선출해서..
huidea.tistory.com
https://velog.io/@jus6886/TabNet
TabNet
TabNet은 tabular 데이터의 훈련에 맞게 설계됐으며 Tree기반 모델의 변수선택 특징을 네트워크 구조에 반영한 모델이다. 이는 딥러닝 모델이 해석하기 어려운 문제를 sequential attention mechanism을 이용
velog.io
https://www.intelligencelabs.tech/a3e8ecf1-0d18-4c69-8df1-2970a65e797a
정형 데이터를 위한 딥러닝: TabNet
Table of contents
www.intelligencelabs.tech
https://themore-dont-know.tistory.com/2
[리뷰]TabNet: Attentive Interpretable Tabular Learning (2021)
논문에 대한 오역, 의역등이 다수 포함되어 있습니다. 댓글로 많은 의견 부탁드립니다 Author : Sercan O. Arık, Tomas Pfister Copyright © 2021, Association for the Advancement of Artificial Intelligence..
themore-dont-know.tistory.com




댓글