
이번 글에서는 자연어처리(Natural Language Processing, NLP)의 기초에 대해 설명하고자 합니다. 자연어처리에 대해 간단하게 설명한 이후, '밑바닥부터 시작하는 딥러닝 2권' 내용을 바탕으로 딥러닝을 적용하기 이전에는 자연어를 어떠한 방식으로 처리했는지 살펴볼 것입니다.
1. 자연어처리
자연어처리란 사람들이 평소에 사용하는 자연어를 컴퓨터가 이해하도록 만드는 기술을 의미합니다. 자연어에는 단어부터 시작하여 형태소, 문장, 문단 등 다양한 단위가 존재하며, 똑같은 단어나 문장이라고 하더라도 문맥 속에서 다른 의미를 가질 수 있습니다. 자연어를 컴퓨터가 이해하도록 만드는 것은 상당히 어려운 문제이기 때문에, 과거부터 다양한 방법들이 제안 및 발전되어 왔습니다. 특히 최근 ChatGPT가 소개되고 성능이 큰 주목을 받으면서, 자연어처리 기술에 대해 많은 관심이 쏟아지고 있는 상황입니다.
자연어처리는 크게 다음과 같은 활용 분야가 존재합니다.
- 검색 엔진 : 검색 텍스트의 자동 완성 기능, 사용자의 검색 의도를 기반으로 관련 결과를 도출
- 번역 : 자연어처리 기술을 바탕으로 단어뿐만 아니라 문법도 고려하여 다른 언어로 번역
- 음성인식 : 음성인식을 통해 뉴스나 날씨 등의 정보를 실시간으로 전달, 차 안에서의 네비게이션 최적 경로 제공
- 챗봇 : 근무 시간에 제한되지 않는 고객 서비스, 휴가와 같은 인사 관리 업무 등에 활용되어 비용 감소 및 서비스 개선에 기여
자연어처리 기술의 발전과정에 대한 흐름은 아래의 그림과 같습니다. 각 방법론에 대한 설명은 그림에 간략하게 나와있지만, 추후 글을 통해 자세히 살펴보도록 하겠습니다. (제가 제작한 그림이므로 사용할 시에는 출처를 표시해 주시길 바랍니다.)

2. 시소러스
Word2Vec같은 딥러닝 기술이 자연어처리에 적용되기 이전에는 시소러스가 자연어처리에 활용되었습니다. 시소러스는 기본적으로 유의어 사전을 의미하며, 동의어(뜻이 같은 단어)나 유의어(뜻이 비슷한 단어)가 하나의 그룹으로 분류되는 특징이 있습니다. 동의어와 유의어만을 고려하는 경우 외에도, ‘상위와 하위‘, ‘전체와 부분‘ 등의 관계도 고려할 수 있습니다. 아래의 그림과 같은 형태로 유의어 집합을 생성한 이후, 각 단어들의 관계를 정의하고 표현하는 그래프를 생성합니다.
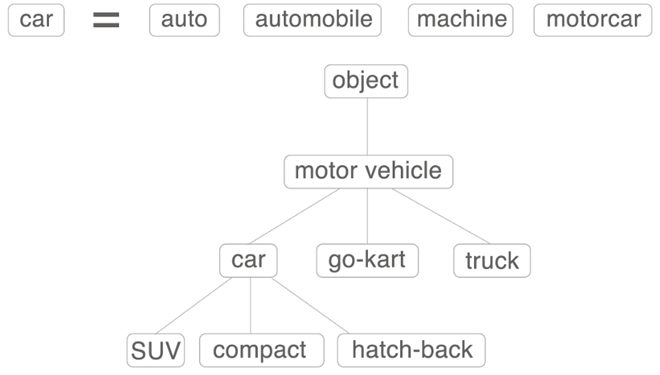
WordNet은 자연어처리 분야에서 가장 유명한 시소러스로, 프린스턴 대학교에서 1985년에 개발되어 이후에도 계속해서 발전하고 있습니다. 유의어 사이의 관계를 그래프로 정의할 수 있고, 각 단어의 유사도를 계산하는 것을 통해 유사한 단어를 파악하는 것이 가능합니다. 활용하기 위해서는 프린스턴 대학에서 제공하는 오픈소스 프로그램을 사용하거나, Python 등의 프로그램에서도 실행할 수 있습니다.
하지만 시소러스는 1) 시대가 변함에 따라 새로 생기는 단어(신조어)나 의미, 사용하지 않게 되는 단어들을 반영하기 어렵고, 2) 각 단어들의 관계를 사람이 수동적으로 정의해줘야 하기 때문에 인적 비용이 많이 들게 되며, 3) 유의어의 경우, 뜻이 비슷하더라도 문맥적인 차이가 존재할 수 있지만, 시소러스는 이러한 차이를 고려하지 못한다는 문제점들이 존재하였습니다.
3. 통계 기반 기법
시소러스의 문제점을 해결하기 위해 등장한 방법이 통계 기반 기법들입니다. 통계 기반 기법이란 단어를 벡터로 표현하기 위해 특정 단어의 주변에 어떤 단어가 몇 번 등장하는지 세어 집계하는 방법으로, 짧은 단어가 아닌 대량의 텍스트인 말뭉치(corpus)가 필요합니다. 말뭉치란 일반적인 텍스트 데이터이지만 자연어에 대한 사람의 지식이 포함되어 있어 단어의 맥락적인 의미를 추출하기 위해서는 필수적입니다.
1) 단어의 분산 표현 및 분포 가설
단어의 분산 표현은 단어의 의미를 정확하게 파악할 수 있는 벡터로 표현하는 것입니다. 색을 (R, G, B) = (170, 33, 22) 형태로 나타내는 것과 같이 단어들을 (오토바이, 자전거, 책상) = (0.76, 0.69, -0.34) 형태로 표현하는 것을 의미합니다. 단어를 벡터로 표현하기 위한 많은 연구 중에서 핵심적인 가설 중 하나가 분포 가설(Distributional Hypothesis)인데, 단어의 의미는 주변 단어에 의해 형성된다는 아이디어에 기반합니다. 주변 단어를 바탕으로 맥락을 파악하기 위해 주변 몇 개의 단어를 포함할지 window 크기를 설정하며, 아래의 그림과 같이 좌우로 설정하는 것도 가능하고 한 방향도 가능합니다.

2) 동시발생 행렬 & 벡터 간 유사도
동시발생 행렬은 말뭉치에 존재하는 각 단어들에 대해 주변에 어떠한 단어들이 있었는지 센 후 집계한 행렬을 의미합니다. ‘you’라는 단어의 경우, [0, 1, 0, 0, 0, 0, 0]이라는 벡터로, ‘say’는 말뭉치에서 두 번 등장하므로 [1, 0, 1, 0, 1, 1, 0] 벡터로 나타낼 수 있습니다.

단어를 나타내는 벡터 간의 유사도를 측정하기 위해서는 유클리드 거리, 내적 등을 사용할 수 있지만 코사인 유사도를 주로 사용하였습니다. 코사인 유사도(Cosine Similarity)는 두 벡터 간의 코사인 각도를 바탕으로 유사도를 계산하는 방법입니다. -1에서 1사이의 값을 가지며, 1에 가까울수록 두 단어 간의 유사도가 높고, 0은 유사도가 전혀 없는 경우, -1은 완전 반대의 의미를 가지는 경우를 의미합니다.

하지만 위의 동시발생 행렬로 코사인 유사도를 구하는 경우, you와 i(0.7071), goodbye(0.7071), hello(0.7071), 각각의 단어 간의 유사도가 동일하게 나오는 문제점이 있기 때문에 동시발생 행렬의 경우에는 개선이 필요했습니다. 또한, 말뭉치에 (the, car, drive)라는 단어가 존재하고 the와 car의 동시발생 빈도가 100, car와 drive의 동시발생 빈도가 40이라고 했을 때, the와 car의 관련성이 높게 측정된다는 문제점이 존재하였습니다.
3) 상호정보량
이에 대한 대안으로 등장한 것이 점별 상호정보량(PMI, Pointwise Mutual Information)으로, 아래와 같은 수식으로 나타낼 수 있습니다. 두 단어의 각 발생 확률(P(x), P(y))과 두 단어의 동시발생 확률(P(x, y))을 비롯하여 단어의 빈도도 고려하였습니다.

만약 두 단어의 동시발생 횟수가 0인 경우, 값이 음의 무한대가 될 수 있기 때문에, 양의 상호정보량(PPMI, Positive PMI)을 사용합니다. 하지만 PPMI 행렬의 경우에도 동시발생 행렬과 같이 단어의 수 n에 따라 크기가 달라지는 n*n 형태의 행렬이므로, 말뭉치 내의 단어가 많아질수록 차원의 크기가 커지는 문제가 존재합니다.
4) 특이값분해 기반 차원 축소
단순 상호정보량만을 계산했을 때는 단어의 수에 따라 차원의 크기도 커지기 때문에, 중요한 정보를 유지하면서 차원을 축소시키는 것이 중요합니다. 여러 가지의 차원 축소 방법 중, 데이터의 분포에서 중요한 축(데이터가 넓게 분포하는 축)을 찾아내는 방법들이 있으며, 그 중 하나가 특이값분해(SVD, Singular Value Decomposition)입니다.
특이값분해는 특정 행렬을 세 행렬의 곱으로 분해하는 방법으로, U와 V는 직교행렬, S는 대각행렬을 나타냅니다. U는 m*m 크기를 가지는 행렬이므로, 단어 간의 상호정보량을 나타내는 공간으로 고려할 수 있습니다. 그중 대각행렬인 S에는 특이값(해당 축의 중요도)이 큰 순서대로 나열되는데, 특이값이 낮은 부분은 활용하지 않는 것을 통해 차원을 축소하는 것이 가능합니다.

실제 코드에서는 U 행렬에서 앞의 일부 컬럼을 추출하는 것을 바탕으로 벡터 값을 얻을 수 있으며, 해당 벡터를 단어의 분산 표현으로 이해할 수 있습니다.
[다음 글]
https://dslyh01.tistory.com/61
[Deep Learning] Word2Vec - CBOW
이전 글에서는 자연어처리에 대한 간단한 설명과 딥러닝이 활용되기 전에는 어떤 기법들이 적용되었는지 살펴봤습니다. 이번 글에서는 대표적인 딥러닝 기반의 자연어처리 기법 중 하나인 Word2
dslyh01.tistory.com
<참고>
https://product.kyobobook.co.kr/detail/S000001810145
밑바닥부터 시작하는 딥러닝 2 | 사이토 고키 - 교보문고
밑바닥부터 시작하는 딥러닝 2 | 직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어 처리다!이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(R
product.kyobobook.co.kr
'Data Science > Deep Learning' 카테고리의 다른 글
| [Deep Learning] RNN (2) | 2024.02.23 |
|---|---|
| [Deep Learning] Word2Vec - skip-gram (0) | 2024.02.20 |
| [Deep Learning] Word2Vec - CBOW (2) | 2024.02.08 |
| [Deep Learning] Variational AutoEncoder(VAE) (2) | 2022.12.06 |
| [Deep Learning] AutoEncoder(오토인코더) (1) | 2022.12.02 |




댓글