이전 글에서는 딥러닝 기반의 자연어처리 기법인 Word2Vec의 개요와 Word2Vec의 대표적인 모델 중 하나인 CBOW(Continuous bag-of-words)에 대해 살펴봤습니다. 이번 글에서는 Word2Vec의 다른 대표 모델인 skip-gram과 기존 Word2Vec을 개선하는 과정에 대해 설명하고자 합니다. 해당 글은 '밑바닥부터 시작하는 딥러닝 2권' 책 내용을 바탕으로 작성하였음을 미리 알려드립니다.
1. skip-gram 모델
CBOW 모델이 맥락으로부터 타겟(중앙 단어)를 추측하는 것이라면, skip-gram 모델은 타겟(중앙 단어)로부터 맥락을 추측하는 기법입니다.

skip-gram 모델은 아래의 그림과 같이 CBOW 모델을 반대로 구성한 형태로, 입력층은 하나이고 출력층이 맥락의 범위에 따라 달라지게 됩니다.

skip-gram 모델을 확률의 관점에서 보면, \( w_t \)가 발생했을 때 \( w_{t-1} \)과 \( w_{t+1} \) 동시에 일어날 확률로 나타낼 수 있습니다. 맥락 내 단어들 간의 관련성이 없고, \( \log xy = \log x + \log y \)라는 log의 특성을 활용하면, 아래와 같은 skip-gram 모델의 손실 함수를 도출하는 것이 가능합니다.

skip-gram 모델은 이론상 CBOW 모델보다 어렵기 때문에, 단어의 분산 표현을 잘 나타낼 가능성이 더 높아 일반적으로 성능이 더 좋다고 합니다. 하지만 맥락의 범위만큼 손실 함수를 계산해야 하기 때문에, CBOW 모델보다는 효율성이 떨어진다는 단점이 있습니다.
2. Word2Vec 개선
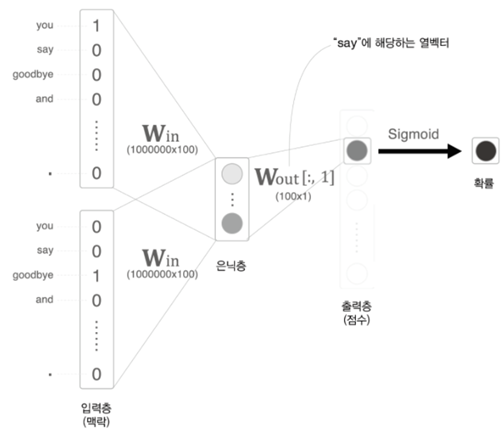
Word2Vec을 이론적으로만 단순하게 구현했을 때는 통계 기반 기법처럼 단어의 수가 많아질수록 연산이 비효율적으로 이루어진다는 단점이 존재합니다. 1) 우선 아래 그림에서 입력층-은닉층에 해당하는 부분입니다. 입력층의 one-hot encoding 과정에서 단어의 수만큼 벡터의 길이도 길어져 많은 메모리를 차지하는 문제와, one-hot 벡터와 가중치 간의 곱셈에서도 상당한 연산이 이루어진다는 문제가 발생합니다. 2) 다음은 은닉층-출력층에 해당하는 부분으로, 은닉층과 가중치 간의 곱과 softmax, 손실 함수 계산 과정에서도 단어의 수에 따라 계산량이 증가합니다. 두 부분의 문제는 각각 Embedding과 네거티브 샘플링을 적용하는 것을 통해 해결 가능합니다.
(1) Embedding
Embedding이란 단어 임베딩(Word Embedding)에서 유래했으며, 단어의 분산 표현과 같이 단어의 밀집 벡터를 의미합니다. 기존 Word2Vec의 입력층-은닉층의 연산 과정은 1) 단어의 one-hot 벡터 생성, 2) one-hot 벡터와 가중치 간의 곱, 두 단계입니다. one-hot 벡터는 해당 단어에 해당하는 값만 1이기 때문에, 위 과정은 결국 단어에 해당하는 가중치 행을 추출하는 것이 끝입니다. 이는 위 기존 과정의 1), 2) 단계가 굳이 필요 없다는 것을 의미합니다.
따라서 아래의 그림과 같이 Embedding 계층에서는 위 과정을 생략하고, 단어의 위치(idx)를 바탕으로 가중치 행을 추출하는 연산만 진행하여 연산의 효율성을 극대화하는 것이 가능합니다. 역전파 과정에서도 해당 단어의 가중치만 갱신하는 식으로 개선할 수 있습니다.

(2) 네거티브 샘플링
네거티브 샘플링은 다중 분류의 문제를 이진 분류 문제로 다루는 것에서부터 시작합니다. 기존 방법은 출력층에서 softmax 함수를 통해 모든 단어의 확률을 구하는 것이었습니다. 하지만 이진 분류를 활용할 경우 해당 단어가 등장하는지 여부만 추측하면 되므로, 타겟에 해당하는 단어만 추출하고 이후의 연산을 진행하여 계산량이 상당히 감소합니다. 이진 분류이기 때문에 softmax 대신 sigmoid를 사용하며, 손실 함수는 동일하게 교차 엔트로피 오차를 적용합니다.
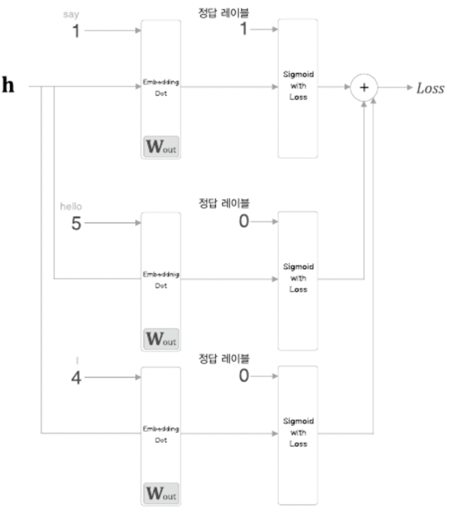
정답에 해당하는 단어에 대해 확률이 1에 가까워지도록 학습하면서, 정답이 아닌 단어들에 대해서도 확률이 0에 가까워지도록 학습하는 과정이 필요합니다. 이때 정답인 단어는 하나이지만 정답이 아닌 단어는 너무 많기 때문에, 모든 단어를 학습하는 것은 비효율적일 수 있습니다. 정답이 아닌 단어, 즉 부정적인 단어를 일부 샘플링(5~10개)하여 학습에 적용하는 것이 네거티브 샘플링입니다.
부정적 단어를 추출할 때 임의로 추출하는 것이 아니라, 단어의 출현 확률 분포를 통해 말뭉치에서 자주 등장하는 단어를 위주로 추출하게 됩니다. 이는 희소한 단어가 실전에서도 거의 등장하지 않기 때문에 학습에 사용하지 않기 위함입니다.

[이전 글]
https://dslyh01.tistory.com/61
[Deep Learning] Word2Vec - CBOW
이전 글에서는 자연어처리에 대한 간단한 설명과 딥러닝이 활용되기 전에는 어떤 기법들이 적용되었는지 살펴봤습니다. 이번 글에서는 대표적인 딥러닝 기반의 자연어처리 기법 중 하나인 Word2
dslyh01.tistory.com
<참고>
https://product.kyobobook.co.kr/detail/S000001810145
밑바닥부터 시작하는 딥러닝 2 | 사이토 고키 - 교보문고
밑바닥부터 시작하는 딥러닝 2 | 직접 구현하면서 배우는 본격 딥러닝 입문서 이번에는 순환 신경망과 자연어 처리다!이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(R
product.kyobobook.co.kr
'Data Science > Deep Learning' 카테고리의 다른 글
| [Deep Learning] RNN (2) | 2024.02.23 |
|---|---|
| [Deep Learning] Word2Vec - CBOW (2) | 2024.02.08 |
| [Deep Learning] 자연어처리(Natural Language Processing, NLP) 기초 (2) | 2024.02.07 |
| [Deep Learning] Variational AutoEncoder(VAE) (2) | 2022.12.06 |
| [Deep Learning] AutoEncoder(오토인코더) (1) | 2022.12.02 |




댓글